
Deep Learning Framework with Apple M1 Support
Started:
In Deep Learning Systems (10-714) at CMU, I learned about the “full stack” of deep learning. Throughout the semester we all built our own deep learning framework according to the NeEDLe spec (Necessary Elements of Deep Learning). By our last assignment, I was able to implement many of the same features as in Pytorch, including support for attention models. One of the assignments involved developing an NDArray backend in CUDA, so Nvidia GPUs could be used for acceleration. For my final project I decided to extend this to M1 Macs.
The following is my team’s writeup. I contributed all the code and performed the benchmarks as well as their analysis.
Metal Backend for Needle Framework
Deep Learning Systems Final Project
Mihir Dhamankar, Siddhant Sapra, and Carson Stuart
Introduction
For our project, we have decided to build a backend for Needle specific to the Apple M1 chip.
The M1 is a chip recently developed by Apple considered to have world’s best CPU performance per watt at the time of its introduction. Furthermore, the Metal Shading Language was developed, which allows one to take advantage of the graphics and compute processing power of the GPU in the M1. It is based on C++.
According to Apple, M1 delivers up to 6x faster GPU performance and up to 15x faster machine learning. Therefore, we expect the M1 chip to outperform the C++ backend for the CPU in our homework.
The M1’s GPU is quite capable as we have seen it efficiently run large language models such as LLaMa 7B. Making Needle run with this hardware is a step in that direction.
Background Research
GPU (Graphics Processing Unit) acceleration has gained prominence in scientific computing due to its parallel processing capabilities. Research has showcased GPUs’ potential in accelerating scientific simulations by orders of magnitude compared to CPUs. The ability to perform numerous calculations simultaneously makes GPUs ideal for computationally intensive tasks in fields like physics simulations, machine learning, and computational biology.
The integration of Metal, Apple’s low-level graphics API, and Metal Shading Language (MSL) allows developers to harness GPU capabilities for general-purpose computing. Apple’s Metal sample code library demonstrates the effectiveness of MSL in performing computations on the GPU. Notably, examples related to “Performing Calculations on a GPU” provide insights into converting C++ code to MSL and setting up GPU pipelines, which aligns with our project’s objectives.
Recent advancements in Apple’s M1 chip introduced a unified memory architecture and powerful GPU cores, revolutionizing GPU computing on Mac systems. The GitHub repository by Lars Gebauer explores leveraging the Metal Shading Language with C++ to accelerate scientific codes specifically on M1-based systems. This repository serves as a valuable resource, illustrating practical implementations and optimizations tailored for the M1 architecture.
MSL offers performance advantages by exploiting GPU parallelism, reducing computation times, and enabling complex computations on GPUs. However, challenges such as optimizing algorithms for GPU parallelism, memory management, and porting existing CPU-based code to MSL exist. Understanding these challenges is crucial in effectively implementing MSL within the Needle framework for our M1 backend.
In summary, GPU acceleration through MSL presents a promising avenue for enhancing computational performance, and the existing research and resources in this domain form a solid foundation for our project’s implementation of an M1 backend for the Needle framework.
Implementation
The Metal framework allows us to write kernel code in MSL very similar to CUDA. For example, this is elementwise addition:
CUDA:
__global__ void EwiseAddKernel(const scalar_t* a, const scalar_t* b, scalar_t* out, size_t size) {
size_t gid = blockIdx.x * blockDim.x + threadIdx.x;
if (gid < size) out[gid] = a[gid] + b[gid];
}
Metal:
kernel void ewise_Add(device const scalar_t* a [[buffer(0)]],
device const scalar_t* b [[buffer(1)]],
device scalar_t* out [[buffer(2)]],
uint index [[thread_position_in_grid]])
{
out[index] = a[index] + b[index];
}
When we initialize the Metal device we can get its command queue. This queue is how instructions are sent to the GPU. After this, our compiled shader library (build/ops.metallib) has to be dynamically loaded. We then create pipelines for each kernel function and store them in a map.
To call these functions on the GPU
- Create a buffer with all the data used in the calculation
- Get the pipeline for the function we want and encode it into something the GPU will understand
- Also encode the data buffer
- Get the thread group and grid sizes
- Add the encoded command and data to the command buffer (part of the command queue) and commit
- Wait until the GPU finishes its calculation
The Metal framework itself uses Objective-C so Metal-cpp uses C to call directly into the Objective-C runtime. This does not add significant overhead.
Installation
- Install XCode
- Install all needle dependencies (cmake, pybind11, pytest)
This code has been tested on MacOS 13.6 with Python 3.11, using a different MacOS version may require a different version of Metal-cpp. Make sure to change line 8 in CMakeLists.txt if using a different version of Python.
src/ndarray_backend_metal.cpp and src/ops.metal are the relevant files for the ndarray backend implementation and kernel code
The only other files modified from our homework implementations were for benchmarking tests
# compiles shader code into build/ops.metallib library, then creates CPU and Metal shared libraries
!make
Once the shared library is created at python/needle/backend_ndarray/ndarray_backend_metal.cpython-311-darwin.so, you can use Needle as normal with the metal() device (similar to the cuda() device).
Benchmarking
The tests we are running in order to evaluate the perforamnce of our new backend are very similar to the tests ran during homework 3. The following code is a template for how we generated our graphs:
matmul_dims = [
50, 100, 500, 1000, 1250, 1500, 1750, 2000, 2500,
]
@pytest.fixture(scope="session")
def execution_times():
cputimes = {}
gputimes = {}
yield cputimes, gputimes
# This will print the execution times after the tests
print("Execution times:", cputimes, gputimes)
plt.plot(cputimes.keys(), cputimes.values(), 'o-', label='CPU')
plt.plot(gputimes.keys(), gputimes.values(), 'o-', label='GPU')
plt.xlabel('Matrix Size (M = N = P)')
plt.ylabel('Execution Time (seconds)')
plt.title('Execution Time vs Matrix Size - matmul on M1')
plt.legend()
plt.show()
NUM_TRIALS = 10
@pytest.mark.parametrize("m", matmul_dims)
def test_matmul(m, execution_times):
for i, d in enumerate([nd.cpu(), nd.metal()]):
execution_time = 0
for _ in range(NUM_TRIALS):
_A = np.random.randn(m, m)
_B = np.random.randn(m, m)
A = nd.array(_A, device=d)
B = nd.array(_B, device=d)
start_time = time.time()
result = A @ B
end_time = time.time()
execution_time += end_time - start_time
execution_time /= NUM_TRIALS
print("Execution time:", execution_time, "seconds")
np.testing.assert_allclose(result.numpy(), _A @ _B, rtol=1e-3, atol=1e-3)
if m not in execution_times[i]:
execution_times[i][m] = []
execution_times[i][m].append(execution_time)
Run:
python3 -m pytest -s -v -k "matmul"
Results
We ran each of these tests 10 times and averaged the results per execution. The M1 tests were run on a 2021 Macbook Pro with an M1 Pro Chip and 16GB RAM. All tests with associated graphs were done with square matrices of the same sizes, but we were able to pass all HW3 and HW4 tests just by replacing “.cuda()” with “.metal()”
M1 GPU
We were able to successfully implement all the same operations as the CUDA and CPU backends.
This graph shows average execution times of matrix multiplication using the Metal backend. 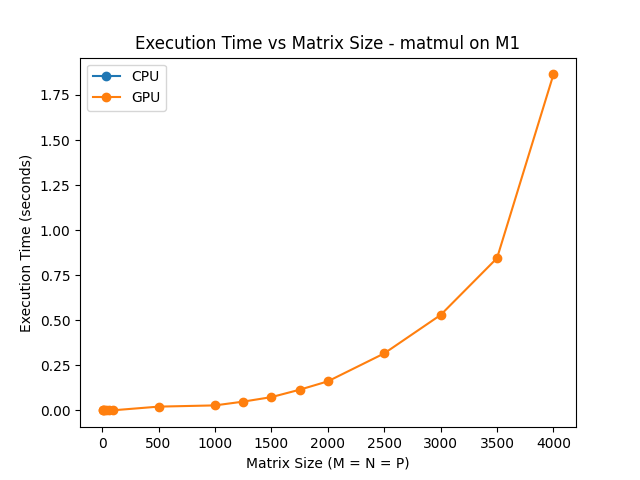
M1 CPU vs GPU
Comparing these times with the M1 CPU’s times clearly shows why GPU acceleration is preferable. Multiplying two 500x500 matrices takes 0.15s on the CPU but only 0.007s on the GPU. This is over a 2x speedup. As the CPU caches fill up, it becomes even slower, giving a 60x speedup for size 1750.
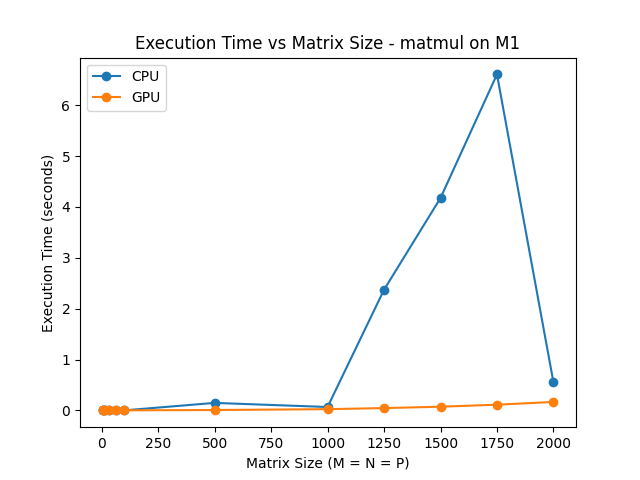
The CPU execution time suddenly drops at size 2000, but this is not a mistake. Further testing showed there was a similar fast execution time for size 3000, but sizes 2500 and 3500 took 20 and 60 seconds each. Our best guess is that this is either due to bugs in our CPU implementation or effect of how the M1 CPU handles caching and swap memory.
Due to a lack of time, we did not get to finish implementing an optimized matmul (we used the naive method). However, we were happy to see that our unoptimized GPU implementation could still compete with Numpy’s optimized CPU implentation. In this test, the CPU line is the execution time of Numpy’s matmul running on the M1 CPU, while the GPU line does the same using Needle and our Metal backend.
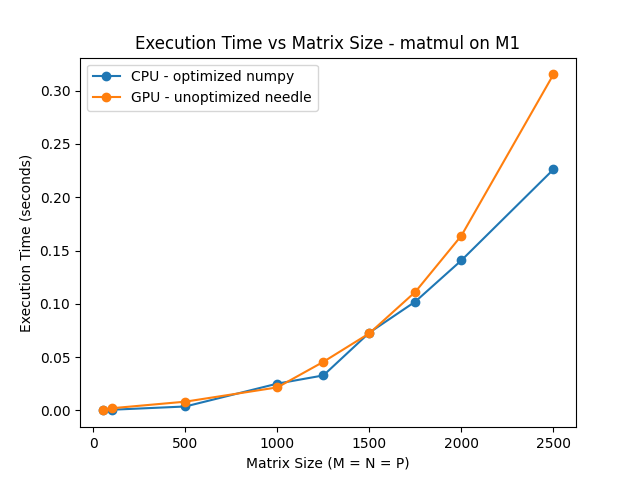
Even without optimized code, the M1 GPU’s capabilities allow it to perform on par with the Numpy on CPU.
Interestingly, our CPU implementation also narrowly beat the GPU one for matmul with sizes < 100x100. This is probably due to the increased overhead in setting up the data buffers and calling kernel functions.
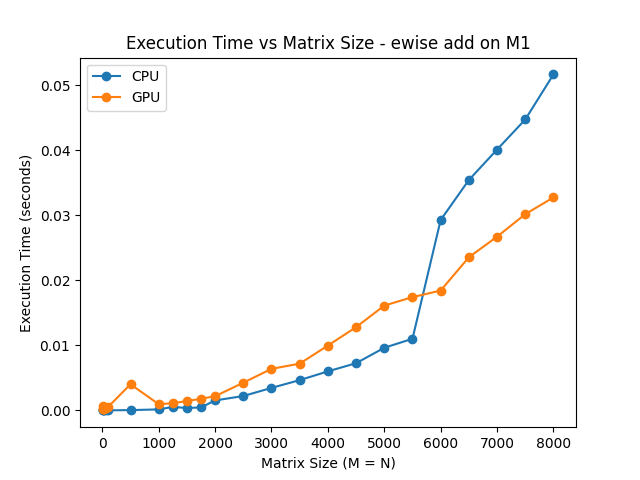
This can also be seen in the execution times for elementwise operations. The following graph of elementwise addition times shows a marked increase in CPU execution time for matrices above the 5000x5000 size. Overhead causes the GPU time to be slightly slower at this size and smaller.
M1 GPU vs Tesla T4 GPU and others
To see if our M1 backend implemetation is efficient, we tested it against the CUDA backend implementation of one of our group members from HW3. We tested the CUDA version on 2 different GPUs.
For the duration of this class, one of our group members (Mihir) used a low end workstation PC with an Nvidia Quadro P1000 GPU to test his code. The other two members used Google Colab, which uses Nvidia Tesla T4 GPUs. The P1000 is significantly weaker than both the M1 and T4 GPUs. Based on FP32 performance, the T4 GPUs used on Google Colab are about 53% faster than the M1. Running the matmul tests, this difference was noticable.
This is how the 3 GPUs compared running matmul:
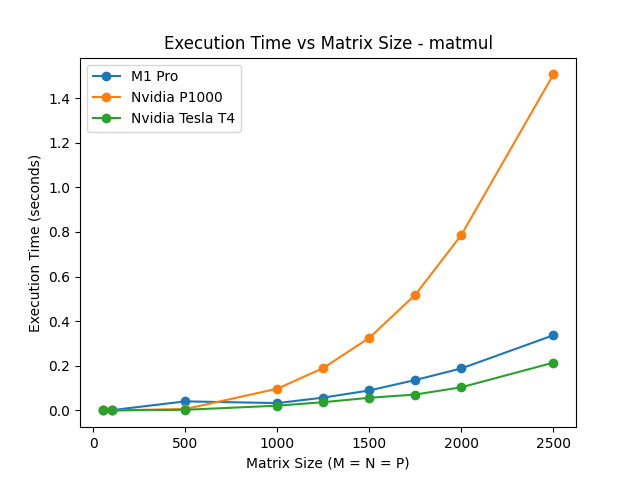
As expected, the P1000 performed significantly worse than the other two, especially with larger matrices. Comparing the 2500x2500 tests, the T4 GPU finished in 0.214s, M1 finished in 0.337s, and P1000 finished in 1.506s. Surprisingly, the T4 performed only 36.5% faster than the M1, hinting that our M1 backend implementation is at least (if not more) efficient at matrix multiplication than our CUDA implementation from HW3.
Empirical Testing and Conclusion
The point of a deep learning framework is to be able to train deep learning models. Though our Needle implementation is not nearly as optimized as Pytorch, we still wanted to test how it would work training a neural network. We started training the ResNet9 CNN from HW4 on an M1 Mac, Mihir’s PC, and Google Colab all using GPU. Mihir’s PC only completed 4 epochs in an hour. The M1 Macbook Pro completed 6 epochs in an hour. Colab completed training (10 epochs) in only 21 minutes.
Doing some digging online, we found many people complaining about M1 being slow at running RNNs, even with more optimized frameworks like Tensorflow-metal, which is maintained by Apple. This means that part of the slowdown may be attributed to factors beyond our control.
Still, our project serves as a proof of concept that using an M1 laptop for tasks related to the Needle framework is feasible. On top of this, the M1 GPU uses less power than the other GPUs.
Future Work
While our implementation of the Metal backend for Needle has shown promising results and marked performance improvements, several areas warrant further exploration:
Our first area of exploration would be leveraging Metal Performance Shaders (MPS). Apple’s Metal Performance Shaders offer optimized implementations of various machine learning operations, including efficient matrix multiplication, convolution, and neural network layers. Integrating MPS within the Needle framework could streamline and boost the performance of these specific operations, potentially further improving computational efficiency.
Our next potential area of exploration is exploring Block Multiplication and Shared Memory. Investigating techniques like block multiplication and utilizing shared memory within the Metal framework can enhance the efficiency of matrix operations, particularly matrix multiplications. Optimizing memory access patterns and utilizing shared memory could further accelerate computations, especially for larger matrices.
Lastly, we would want to explore creating and training transformer models and RNNs. Expanding the scope of our testing to include training more complex models like Transformer architectures and recurrent neural networks (RNNs) could provide insights into the performance and efficiency of these models on the M1 GPU. Further optimizations tailored to these specific architectures could be explored.
References
- https://developer.apple.com/videos/play/wwdc2022/10160/ - Explains the basics of Metal-cpp
- https://larsgeb.github.io/2022/04/20/m1-gpu.html - Explains how to use Metal-cpp for scientific computing by porting Apple’s Objective C tutorial code into C++. It also helped with compiling the shaders and host code for the first time and understanding how to efficiently call shaders without rewriting code.
- https://gadgetversus.com/graphics-card/nvidia-tesla-t4-vs-apple-m1-pro-gpu-16-core/ - Suggests Colab’s Tesla T4 is 53% faster than an M1 Pro (based on FP32 performance)